

Author
Team DAISYS
Category
API Release
The DAISYS voice generation and text-to-speech API was updated to version 1.1, and it brings a set of improvements aimed at making speech output more natural and precise. This update focuses on giving developers better tools for handling timing, pronunciation, and lowering our latency by connecting to our services via websockets for streaming purposes.
Whether you're working on real-time applications or fine-tuning speech for specific use cases, version 1.1 makes it easier to get the exact delivery you're after.
Here’s a quick rundown of what’s new:
🧠 Better Control Over Pronunciation and Prosody
New tag support means you can now fine-tune how speech is generated.
<w> tag:
Helps you deal with heteronyms—words that are spelled the same but have different pronunciations depending on context (like lead the team vs a lead pipe). With this tag, you can explicitly tell the system which pronunciation you want.<emphasis> tag:
Lets you control emphasis with options like strong, medium, or down. You can also add a pause right after the word for extra effect.<break> tag:
Adds natural-sounding pauses between words or phrases, with adjustable strength. Handy for improving pacing or separating thoughts in generated speech.
These tags make it easier to shape the rhythm and feel of the voice, especially if you’re going for something more conversational or expressive.
⚡ WebSocket Support for Low-Latency Streaming
You can now connect directly to a worker node via WebSocket and stream audio as it’s being generated.
Before, you could get audio simply as a streamed wav file by opening an early HTTP request to our streaming server and waiting for it to deliver the first bytes it receives from a worker node—this is still the lowest complexity approach to streaming that we support. But now, with a direct WebSocket connection to the worker itself, there’s no streaming server in the middle, which means getting the audio as soon as it’s generated.
That’s great if you’re building anything interactive or time-sensitive—like a voice chatbot or live audio app.
There’s also a sample web app included that shows how to use the new WebSocket interface. So if you’ve been wanting to experiment with real-time TTS, this makes it much easier to get started.
(And if you prefer the HTTP streaming method, that’s still supported too, while batch style jobs continue to get distributed over our worker nodes for maximum throughput.)
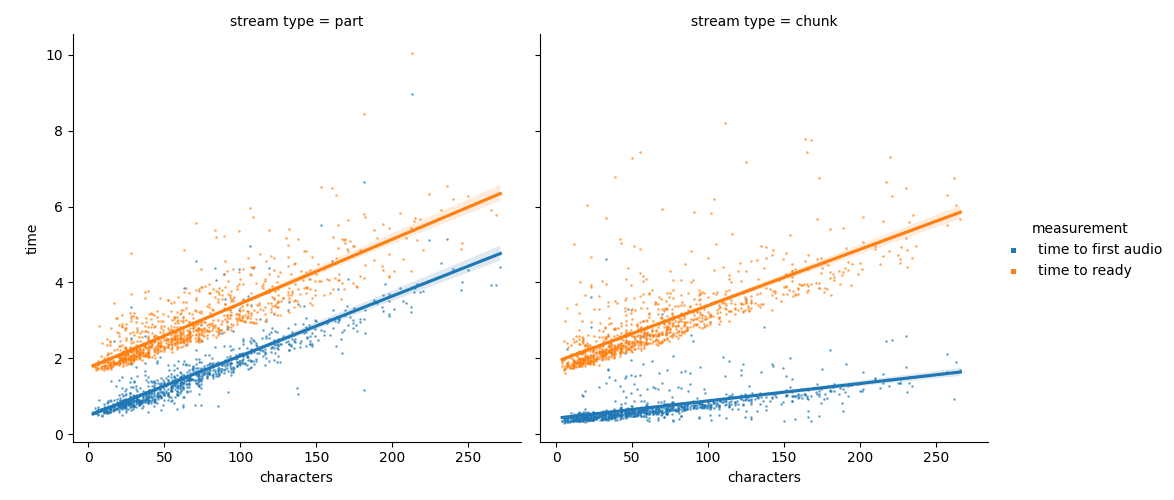
This graphic shows the latency achievable with our new chunk-based streaming mode. We support two methods: in “part” mode each sentence is completed before audio is delivered, which takes some time in exchange for simpler front-end code. On the other hand chunk-based mode delivers the initial audio much faster and less dependent on the sentence length, so you can start playback as quickly as half a second after the request is made.
⏱️ Faster Voice Generation with example_take
This one’s a nice quality-of-life improvement: the generate_voice endpoint now accepts an example_take parameter.
Typically when generating a voice one wants to immediately hear it, so an example such as “Hi, this is my voice” is always generated. With this change you can:
Provide your own text and prosody when generating a sample voice.
Which allows to skip the extra step of generating a voice first, then a take.
Effectively cutting down latency and simplifying your voice design workflow.
Basically, it gives you a one-step way to test a voice with the actual content you plan to use, without needing multiple requests.
💬 Bonus: Conversational Model in Beta
We’re also quietly testing a beta version of our conversational model. It’s designed to work alongside the voice generation tools and add more natural, back-and-forth dynamics to your voice apps. If you’re interested in trying it out early or giving feedback, definitely reach out—we’d love to hear from you.
In Short
Daisys API 1.1 adds a lot of flexibility and speeds things up across the board:
More expressive control over pronunciation and pacing.
Real-time audio streaming with WebSocket support.
Simpler and faster voice generation setup.
(And a peek at what’s coming next with our beta conversational model 👀)
If you're building anything with voice, this release is definitely worth checking out.
Explore more in the docs, pip install the package from PyPI, or check out the code and examples on GitHub. And if you want a faster way to test the API without coding, try it in your browser with SPEAK.